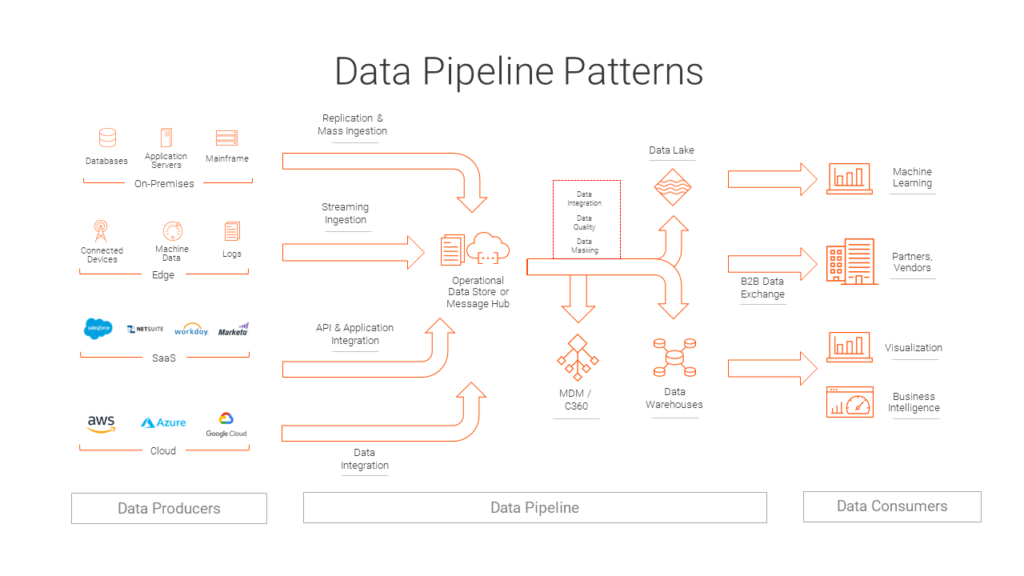
Data Pipeline Architecture
Transform your data infrastructure with robust ETL/ELT pipelines that seamlessly integrate multiple sources, ensure data quality, and deliver reliable insights at enterprise scale.
Transform your data infrastructure with robust ETL/ELT pipelines that seamlessly integrate multiple sources, ensure data quality, and deliver reliable insights at enterprise scale.
Our data pipeline architecture service transforms disconnected data sources into a unified, accessible, and reliable data ecosystem. We design and implement sophisticated ETL/ELT processes that handle complex data transformations while maintaining data integrity and performance.
Our methodology combines industry best practices with cutting-edge technologies to deliver pipeline architectures that scale seamlessly with your business needs.
Connect and harmonize data from databases, APIs, files, and streaming sources with automated schema detection and mapping.
Sophisticated data transformation capabilities including cleaning, enrichment, aggregation, and format conversion with business rule validation.
Intelligent workflow orchestration with dependency management, error handling, and comprehensive monitoring for optimal performance.
Our data pipeline solutions deliver quantifiable improvements in operational efficiency, data accuracy, and business intelligence capabilities.
Unified 15 disparate data sources into a single analytics platform, reducing report generation time from days to minutes.
Implemented real-time inventory pipeline processing 2M+ transactions daily with 99.99% accuracy.
Automated regulatory reporting pipeline reducing compliance preparation time by 80%.
Our systematic approach ensures optimal pipeline architecture from initial assessment through deployment and ongoing optimization.
Comprehensive analysis of existing data sources, formats, and quality
Define processing requirements, SLAs, and business objectives
Design optimal pipeline architecture and technology stack
Build ETL/ELT processes with transformation logic and validation rules
Comprehensive testing including unit, integration, and performance tests
Configure monitoring, alerting, and logging systems
Gradual rollout with safety checks and fallback procedures
Optimize performance based on real-world load patterns
Team training and documentation handover
Discover how our comprehensive data engineering services work together to create a complete data ecosystem.
Robust ETL/ELT pipelines for seamless data integration and processing across multiple sources.
Scalable cloud architectures optimized for high-performance data processing and cost efficiency.
Streaming solutions that process and analyze data as it arrives for instant insights and responses.
We leverage industry-leading tools and frameworks to build robust, scalable data pipelines that meet enterprise requirements.
Tools selected for optimal processing speed, memory efficiency, and scalability characteristics.
Enterprise-grade solutions with proven track records in mission-critical environments.
Seamless integration with existing systems and future-proof architecture design.
Our implementation follows strict safety protocols to ensure zero data loss, minimal downtime, and complete system integrity.
Continuous data backups with point-in-time recovery capabilities
Complete audit trail of data transformations and movements
Multi-stage validation to ensure data integrity at every step
Instant rollback capabilities to previous stable states
We guarantee 99.95% pipeline uptime with automated failover, complete data integrity protection, and 24/7 monitoring. Any SLA breach results in service credits and immediate issue resolution.
Our data pipeline architecture service is designed for organizations facing complex data integration challenges and scaling requirements.
Large companies with multiple data sources, complex business processes, and high-volume data processing requirements.
Fast-growing companies needing to consolidate data sources and automate reporting processes for better decision making.
Industries with heavy data requirements like finance, healthcare, retail, and manufacturing requiring real-time insights.
Advanced monitoring and analytics provide complete visibility into pipeline performance, data quality, and business impact.
Tailored reports and dashboards designed for your specific business requirements, with automated delivery to stakeholders and integration with existing BI tools.
Comprehensive post-implementation support ensures optimal performance, continuous improvement, and seamless operation of your data pipelines.
Continuous monitoring with proactive alerts and optimization recommendations to maintain peak performance.
Scheduled maintenance activities including updates, security patches, and performance optimizations.
24/7 technical support with guaranteed response times and direct access to our engineering team.
Get answers to common questions about our data pipeline architecture service and implementation process.
Transform your data integration with our expert pipeline architecture service. Get robust, scalable solutions that deliver results from day one.